- Research
- Open access
- Published:
Energy consumption optimization management mechanism based on drug green crowd data in biological pharmaceutical cloud environment
EURASIP Journal on Embedded Systems volume 2017, Article number: 21 (2017)
Abstract
For satisfying the network trend and intelligent demand of biopharmaceutical, we proposed the energy optimization consumption and management scheme of the drug green crowd data in the biological pharmaceutical cloud environment. First, the biopharmaceutical process are mapped to the cloud platform, which can not only adapt to the revolutionary changes in the way of biopharmaceutical research and but also build a network management platform for pharmaceutical research and development. Secondly, based on the green crowd, we reconstruct the organization structure of the cloud platform, production process, and value chain-driven portfolio, etc. Then, we divide the core of the cloud platform architecture into five substages. The green screening, reorganization, and crowd data processing will be completed by the cooperation of these stages. Finally, the drug green crowd architecture is embedded into the time domain conversion interface and the state transition interface. In addition, the state energy consumption model of the biological pharmaceutical cloud platform is constructed. The experimental results show that compared with the traditional task-driven energy consumption management mechanism, the proposed management mechanism can ensure higher throughput, higher effective flow rate, and higher effective energy consumption ratio.
1 Introduction
With the rapid development of computer network and parallel computing [1], how to apply them to the biopharmaceutical industry [2, 3] has become a research focus in improving the production efficiency of the biopharmaceutical industry [4] and reducing the cost of research and development. The authors of article [5] described a cloud-based workflow for genome annotation processing that is underpinned by MeDICi—a middleware designed for data-intensive scientific applications. The novel visualizations were proposed in article [6] to facilitate manual gating. This method views a single data of one biological sample as a high-dimensional point cloud. The novel cloud-based medicine recommendation was proposed by Zhang Y et.al [7], which can recommend users with top-N related medicines according to symptoms. Hans A et.al [8] studied the various biomedical services that have been provided on cloud and made a comparative study of these cloud-based biomedical services. The novel method for optimizing the energy consumption of robotic manufacturing systems was proposed in [9], which embedded detailed evaluations of robots’ energy consumptions into a scheduling model of the overall system. Li M et.al [10] proposed a new multi-hop cognitive cellular network architecture to facilitate the ever exploding data transmissions in cellular networks. A novel power optimization utility software was proposed by Hazel T et.al [11], which considered the different energy costs across the pipeline pump/compressor stations, utility contracts, and pump/compressor efficiency. The analytical framework for the total energy consumption of an amplify-and-forward multi-hop network was proposed in article [12] by employing M-ary quadrature amplitude modulation, which can satisfy the average bit error rate requirement at the destination over Rayleigh fading channels.
The article [13] investigated the possibility of using a new Smart-ECO model, consisting of a smart device, in order to optimize the electricity consumption per appliance. A method of production scheduling oriented to energy consumption optimization for process industry was proposed in article [14], which is based on self-adaptive differential evolution algorithm. The authors of article [15] designed a workload model and a memory energy consumption model based on software-defined networking architecture. In article [16], the optimization of energy consumption and environmental impacts of chickpea production was conducted using data envelopment analysis and multi-objective genetic algorithm techniques.
Based on these findings, we proposed the energy consumption optimization management mechanism with drug green crowd data for biological pharmaceutical cloud environment. The rest of the paper is organized as follows. Section 2 describes the pharmaceutical green crowd architecture in the cloud environment of biological medicine. Section 3 proposes the energy consumption optimization management mechanism of drug green crowd data. The performance evaluation is shown in Section 4. Finally, Section 5 concludes the paper.
2 Pharmaceutical green crowd architecture in the cloud environment of biological medicine
2.1 Biopharmaceutical cloud platform
It is difficult to find new chemical entities in biological pharmacy. This issue extended the research and development time of new drugs and increased the research and development (R & D) costs. At the same time, the interference of external environmental factors and the variability of the biological pharmaceutical platform cannot be predicted. Therefore, compared with the traditional biological pharmaceutical technology, the recent pharmaceutical research and development of the pharmaceutical industry tends to be networked and intelligent. The network of biopharmaceutical [17] was reflected in the revolutionary changes and the network management way of biological research and pharmaceutical research and development. Intelligent [18] includes pharmaceutical platform organization structure, production process, and value chain-driven combination and other aspects of the intelligent level.
In order to give full play to the network and intelligence of the driving force of biopharmaceutical, the biopharmaceutical platform is gradually changing. On the one hand, in order to reduce R & D costs, shorten the development cycle, and decentralize R & D risk, the independent laboratory model gradually transferred to the direction of cooperation in R & D [19]. On the other hand, the application of a large number of new technologies and methods would provide a comprehensive [20] experimental platform. This platform can effectively shorten the time of drug development and improve the range of drug types.
The cloud platform has the advantages of the above two aspects. The combination of biopharmaceutical and cloud platform can not only build the cloud scale of biopharmaceutical research and development platform but also provide a comprehensive interactive platform for drug experiment.
Biopharmaceutical cloud platform is a very complex cloud environment. The cloud environment is involved in different aspects of biological pharmaceuticals, as shown in Fig. 1. Specific contents are as follows:

Biopharmaceutical cloud platform
-
(1)
Biological pharmaceutical technology with high difficulty and complexity.
-
(2)
Experimental platform of biopharmaceutical technology
-
(3)
The intelligent management of biological pharmaceutical cloud platform
-
(4)
Cloud platform for the virtual environment of various diseases of experimental drug performance, such as cancer, genetic disease, cardiovascular disease, infection, and immunity.
-
(5)
Network cloud platform for all kinds of drugs and pharmaceutical process. The adaptability of the biological pharmaceutical cloud platform can be obtained by Eq. (1).
$$ \left\{\begin{array}{l}{E}_{\mathrm{N}}=\sqrt{B\cdot {\displaystyle \sum_{i=1}^n{C}_i\cdot {I}_C}}\\ {}{E}_{\mathrm{M}}={V}^2\cdot {\displaystyle \sum_{j=1}^m{B}_i}\end{array}\right. $$(1)
Here, E N said network cloud adaptation. E M denotes smart cloud adaptation. B represents the fitness of biopharmaceutical technology. C represents the fitness of the drug experimental platform. Parameter n represents the number of test objects on the platform. I C indicates intelligent cloud weight. V represents the balance of cloud platforms. Parameter m says share of biotech drugs.
2.2 Drug green crowd architecture
There are P servers in the biopharmaceutical cloud platform. Biopharmaceutical networking requires f virtual clouds with high frequency and large memory. The cloud platform centric server can support L data link with parallel transmission. The intelligent model of cloud platform center can satisfy the K biopharmaceutical process in parallel. All biopharmaceutical industry processes are in the same network environment and cloud environment.
Drug performance vector PB = (PB0, PB1, …, PB n-1). We need to design n virtual test cloud environments that must satisfy the requirements of drug performance testing. The real-time available memory resources and processor utilization of the cloud platform server can be obtained by Eq. (2). From Eq. (2), the more the parallel data link, the lower the utilization rate is. It is difficult to improve the structure of large-scale biopharmaceutical industry chain.
Here, I M is used to show the memory utilization. D represents the data size of each data link. δ denotes data link data utilization. ε represents the mutual interference of parallel data chains. R CPU indicates processor utilization. U represents the efficiency of the use of each test server.
So, we proposed the green crowd architecture based on the green drive of drug production, as shown in Fig. 2. Here, the medicine green crowd module has five substeps, which are S1, S2, S3, S4, and S5. The data of pharmaceuticals was sent to S1. The session of pharmaceuticals was sent to S2 and forwarded to S4. The evaluation of pharmaceuticals was sent to S3 and forwarded to S5. The final results of medicine green crowd module were sent to the crowd cloud.

Architecture of medicine green crowd module
The architecture core in Fig. 2 is divided into five stages. According to Eq. (3), stages S1, S2, and S4 complete the green screening and reorganization. According to Eq. (4), stages S3 and S5 complete the crowd data processing.
Here, D g represents the data sequence of the reorganization. ΔD is the mean value of data sequence after green filter.
Here, D C expressed crowd data sequence. Parameter E expresses crowd computation overhead. Parameter a represents the length of the vector for the performance evaluation of the drug. Parameter P represents a vector of drug performance evaluation.
3 Energy consumption optimization management mechanism of drug green crowd data
Biopharmaceutical cloud platform and drug green crowd data processing is a complex organic system composed of a number of dynamic regulatory modules. The module of the system has a number of life cycle states. Each life cycle state generates the corresponding energy consumption. The energy consumption of the power conditioning module can be divided into five basic stages: initialization, green filtering, networking, crowd reconstruction, and data processing.
The process of crowd data processing can be divided according to the characteristics of biological pharmaceutical cloud platform. Energy consumption and performance characteristics under different conditions are as follows:
-
(1)
Energy consumption of data processing state will be the highest. The state is the interface between the cloud platform and the outside world.
-
(2)
The lowest energy consumption are the initialization state and networking state. These states are used to realize the network of biological pharmacy. The energy consumption of green filter state is between initialization state and reconstruction crowd state, which is used to provide the raw data for the crowd data processing. Conversion between the various states requires time and energy consumption. The transition between the green filter state and the reconstruction crowd state is a linear time domain, which is the minimum energy consumption of linear transformation. Different states can be converted to each other through the conversion interface. State transition energy consumption is negligible. The conversion of nonlinear conversion between different states is converted to linear time domain via conversion interface. The state energy consumption model of biopharmaceutical cloud platform is shown in Fig. 3. There are five states in biopharmaceutical cloud platform, which are initialization, green filter, crowd reconstruction, networking, and data processing. The numbers of arrows express the state transition priority. Time domain conversion interface and state transition interface as shown in Fig. 4. Here, the data was sent by the sender and forwarded from α and β to destination through the state interfaces, which include the filter and crowd model.
Fig. 3 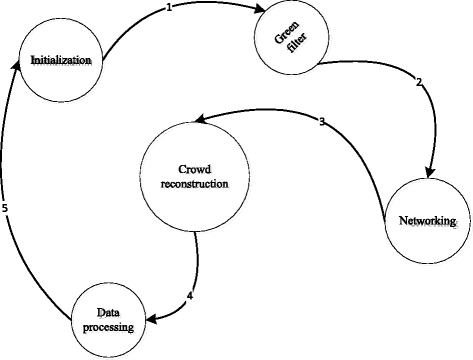
State of energy consumption model of the biopharmaceutical cloud platform
Fig. 4 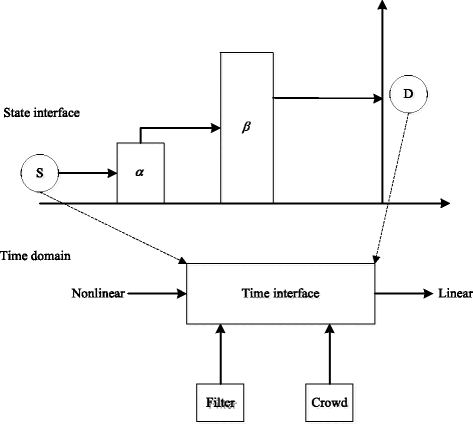
Conversion interface


The energy consumption optimization of the green crowd data would be completed according to Eq. (5).
Here, the curve integral is used to optimize the energy consumption of the biopharmaceutical cloud platform and the drug green crowd data processing.
4 Performance verification of energy consumption optimization management algorithm
Aiming at the biopharmaceutical cloud platform, the experiment focuses on the energy consumption optimization management mechanism of the medicine green crowd data and the comparison between the performance of the proposed energy consumption optimization management mechanism based on drug green crowd data in the biological pharmaceutical cloud environment denoted as ECO-DGC and task-driven energy consumption management strategy denoted as TDE-MS. The task-driven energy management strategy drives the energy management of cloud platform by using a concurrent task of the cloud platform. In order to deeply evaluate the energy optimization consumption performance of the proposed optimization strategy, we used the effective flow ratio, system throughput, and system evaluation metrics and compared with the task-driven energy management strategy.
The configuration of the server configuration used by the biopharmaceutical cloud platform is as shown in Table 1. In the server, the memory data access is based on the traditional memory architecture of the crowd data access operation delay. Internal bus energy consumption and external communication serial port bus energy consumption is related to time domain.
Figure 5 shows the effective flow comparison of the cloud platform. The effective flow ratio of the proposed scheme in large memory (512 MB) is significantly higher than that of the task-driven scheme. With the increased number of concurrent tasks, most of the traffic flow in the task-driven scheme is in the failure state, and the resource utilization rate of the cloud platform is severely reduced. As a result, the system throughput rate of the proposed scheme is better than that of the task-driven scheme. In addition, the task-driven scheme, even if it is a high throughput rate, the effective flow ratio is low, so there is serious waste of system energy (See Fig. 6). In the biopharmaceutical cloud platform, the proposed scheme is deployed on P servers. Biopharmaceutical network is equipped with the f virtual cloud with high frequency and large memory. The cloud platform center server can support the L data link parallel transmission. The intelligent model of cloud platform center can satisfy the K biopharmaceutical process in parallel. All biopharmaceutical industry processes are in the same network and cloud environment.

Effective flow ratio

System throughput rate
Figure 7 illustrates the total cloud platform energy consumption of the two schemes. The proposed scheme can improve the performance of the system while saving energy consumption more than the task-driven energy consumption management strategy. Along with the increase of the memory space and the green crowd data, the energy-saving effect is more and more obvious. The energy-saving effect of the task-driven energy management program is very poor for large memory space. The proposed scheme is based on the power regulation of the drug green crowd data. The energy consumption of each module is divided into five stages: initialization, green filtering, networking, crowd reconstruction, and data processing. The process of crowd data processing can be divided into different progress according to the characteristics of biological pharmaceutical cloud platform. Such partitioning and segmentation are more suitable for large memory space and large data.

System effective energy consumption ratio
5 Conclusions
In order to shorten the development cycle and reduce the cost of pharmaceutical industry, we proposed the energy consumption optimization management mechanism of the medicine green crowd data in the biological pharmaceutical cloud environment. In order to shorten the development cycle and reduce the cost of pharmaceutical industry, we proposed the energy consumption optimization management mechanism of the medicine green crowd data in the biological pharmaceutical cloud environment. On the one hand, the cloud platform was proposed to satisfy the revolutionary changes in the way of biological and pharmaceutical research and development mode of network management requirements. Biopharmaceutical are mapped to the cloud platform, which include the definition of the organizational structure of the cloud platform, production process, and value chain-driven portfolio, etc. On the other hand, the cloud platform architecture core is divided into five stages. Green screening, reorganization, and crowd data processing were completed. We proposed the drug green crowd architecture based on the green drive of drug production. Finally, the state energy consumption model of biopharmaceutical cloud platform is constructed based on the time domain interface and the state transition interface. After many experiments and statistics, we found that the proposed management strategy can solve the management problem of the throughput, flow rate, and energy consumption of different memory spaces and different data scales.
References
DC Marinescu, Parallel and distributed computing: memories of time past and a glimpse at the future[C]//IEEE, International Symposium on Parallel and Distributed Computing (IEEE, Porquerolles Island, 2014), pp. 14-15
H Lee, Y Yang, H Chae et al., BioVLAB-MMIA: a cloud environment for microRNA and mRNA integrated analysis (MMIA) on Amazon EC2]. IEEE Trans. Nanobioscience 11(3), 266–272 (2012)
PC Church, AM Goscinski, A survey of cloud-based service computing solutions for mammalian genomics. IEEE Trans. Serv. Comput. 7(4), 726–740 (2014)
MB Greer, M Rodriguezmartinez, J Seguel, Synthetic biology driven by harnessing forces of disruptive innovation[C]//International Conference on Social Computing (IEEE, Washington, 2013), pp. 840-845
I Gorton, Y Liu, Y Jian, et al, Towards composing data aware systems biology workflows on cloud platforms: a MeDICi-based approach[C]//IEEE World Congress on Services (IEEE Computer Society, Washington, 2011), pp. 184-191
Q Peng, Unfold high-dimensional clouds for exhaustive gating of flow cytometry data. IEEE/ACM Trans. Comput. Biol. Bioinform 11(6), 1045–1051 (2014)
Y Zhang, L Wang, L Hu et al., COMER: Cloud-based medicine recommendation[C]//International Conference on Heterogeneous NETWORKING for Quality (Reliability, Security and Robustness. IEEE, 2014)
A Hans, S Kalra, Comparitive analysis of various cloud based biomedcial services[C]//International Conference on Medical Imaging, M-Health and Emerging Communication Systems (IEEE, Berlin, 2015), pp. 386 - 390
A Vergnano, C Thorstensson, B Lennartson et al., Modeling and optimization of energy consumption in cooperative multi-robot systems. IEEE Trans. Autom. Sci. Eng 9(2), 423–428 (2012)
M Li, P Li, X Huang et al., Energy consumption optimization for multihop cognitive cellular networks. IEEE Trans. Mob. Comput. 14(2), 358–372 (2015)
T Hazel, M Ford, G Stanley et al., Pipeline energy consumption optimization: a novel power optimization utility software. IEEE Ind. Appl. Mag. 20(20), 66–76 (2014)
O Waqar, MA Imran, M Dianati et al., Energy consumption analysis and optimization of BER-constrained amplify-and-forward relay networks. IEEE Trans. Veh. Technol. 63(3), 1256–1269 (2014)
R Malekian, DC Bogatinoska, A Karadimce, et al, A novel smart ECO model for energy consumption optimization. Elektronika Ir Elektrotechnika. 21(6),75–80 (2015)
L Zhang, Y Luo, Y Zhang et al., Production scheduling oriented to energy consumption optimization for process industry based on self-adaptive DE algorithm. Int. J. Control Autom 8(2), 31–42 (2015)
HY Peng, G Chen, YH Zhang et al., A new data center memory energy consumption optimization strategy in SDN. Clin. Pharmacol. Ther 37, 705–706 (2015)
B Elhami, A Akram, M Khanali, Optimization of energy consumption and environmental impacts of chickpea production using data envelopment analysis (DEA) and multi objective genetic algorithm (MOGA) approaches. Inform. Proces. Agric 3(3), 190–205 (2016)
H Chen, S Xu, Empirical study on financial competitiveness of listed bio-pharmaceutical companies in China[C]//Third International Conference on Multimedia Information NETWORKING and Security (IEEE Computer Society, Shanghai, 2011), pp. 258-260
Z Liu, Z Ma, A growth study of bio-pharmaceutical companies on the SME Board in China[C]//Seventh International Joint Conference on Computational Sciences and Optimization (IEEE, Beijing, 2014), pp. 233-236
YH Lin, CF Hong, Efficiency and productivity of publicly-traded bio-pharmaceutical companies in Taiwan[C]//IEEE International Conference on Industrial Engineering and Engineering Management (IEEE, Singapore, 2015), pp. 1328–1331
D Dey, J Kohoutek, RM Gelfand, et al, Integration of plasmonic antenna on quantum cascade laser facets for chip-scale molecular sensing[C]//Sensors, 2010 IEEE (IEEE, Waikoloa, 2010), p. 454-458
Authors’ contributions
The design and research of energy consumption optimization crowd management mechanism were carried out by SW, and the improvement of drug green data was done by LH and GC. The experiment and evaluation of the proposed scheme in the biological pharmaceutical cloud environment were done by all the authors. This manuscript had been prepared and checked by all of the authors together. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Wang, S., He, L. & Cheng, G. Energy consumption optimization management mechanism based on drug green crowd data in biological pharmaceutical cloud environment. J Embedded Systems 2017, 21 (2017). https://doi.org/10.1186/s13639-017-0071-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13639-017-0071-0