- Research
- Open access
- Published:
Backscattering UWB/UHF hybrid solutions for multi-reader multi-tag passive RFID systems
EURASIP Journal on Embedded Systems volume 2016, Article number: 10 (2016)
Abstract
Ultra-wideband (UWB) technology is foreseen as a promising solution to overcome the limits of ultra-high frequency (UHF) techniques toward the development of green radio frequency identification (RFID) systems with low energy consumption and localization capabilities. While UWB techniques have been already employed for active tags, passive tags solutions are more appealing also due to their lower cost. With the fundamental requirement of maintaining backward compatibility in the RFID domain, we propose a hybrid UWB/UHF architecture to improve passive tag identification both in single-reader and multi-reader scenarios. We then develop two hybrid algorithms: the first one exploits the UWB signal to improve ISO/IEC 18000-6C UHF standard, while the other one exploits UWB to enhance a compressive sensing (CS) technique for tag identification in the multi-reader, multi-tag scenario. Both solutions are able to improve success rate and reading speed in the tag identification process and reduce the energy consumption. The multi-reader version of the proposed approaches is based on a cooperative scheme in order to manage reader-tag collisions and reader-reader collisions besides the typical tag-tag collisions. Furthermore, timing synchronization non-idealities are analyzed for the proposed solutions and simulation results reveal the effectiveness of the developed schemes.
1 Introduction
In recent years, systems employing radio frequency identification (RFID) technology have been growing exponentially, spanning from inventory control to any application nowadays using the Internet of Things paradigm.
The most common RFID system architecture consists of a single radio frequency device, named reader, and a population of electromagnetic tags. Each tag is attached to an object to univocally identify it. The tags are classified into three categories depending on the sources of the operating power: passive, semi-passive, and active.
Passive tags systems have limited link budget [2]; however, they are attracting attention due to their low cost and long life. The reader first energizes passive tags by means of electromagnetic energy and then identifies the objects by collecting unique IDs stored in the tag’s memory.
The adoption of ultra-wideband (UWB) technology has been envisaged as a promising solution to overcome the limits of ultra high frequency (UHF) techniques toward the definition of green RFID systems. Reducing energy consumption is also becoming a demanding requirement, and consideration of the environmental impact of RFID systems (e.g., through the use of recyclable materials) [3, 4] is also a major concern: UWB-based solutions would be useful on this purpose. Moreover, the capability of localizing and tracking passive (or semi-passive) devices through UWB signals is a key feature for several types of applications and is also useful to improve the performance of the existing systems [5].
UWB-based solutions have been already employed for active tags [6, 7] due to their low power consumption; however, passive tag solutions are envisioned as preferable due to their low cost.
Anyway, UWB passive solutions [3] are under investigation and show several drawbacks, such as (i) poor link budget with consequent difficult signal detection at the reader receiver, (ii) complex detection of multiple tags, which would require several processing units at the reader receiver, each one tuned on the specific tag code, (iii) the problem of extracting energy from UWB signals due to regulatory issues. Thus, a hybrid UWB/UHF architecture could be useful to exploit UHF signal to transfer the required amount of energy to the tag.
However, the possible integration of a UWB module with the existing UHF RFID standard technology has not been investigated yet and is one of the targets of the Green Tags (GRETA) project [8]. A few alternatives of hybrid UWB/UHF tag architectures have been investigated [8, 9] with UHF only used for energy transfer or with the UHF section providing also the communication capability. We here consider a UHF module for energy transfer and communication for tags identification, while an UWB module is used to assist and improve such tag identification process.
We develop two hybrid UWB/UHF solutions: one of those exploits UWB signals to enhance the standard ISO/IEC 18000-6C UHF, which employs a Framed-Slotted Aloha (FSA) collision arbitration with dynamic frame adaptation. The other one improves a compressive sensing (CS)-based solution in the multi-reader, multi-tag scenario [10] by also considering synchronization errors.
In the first case, we propose an enhanced version of the adaptive Q-algorithm enforced by the EPCglobal Generation 2 protocol. The proposed solution is based on an UWB-aided identification procedure that supports tag population estimation and ranging to improve the tag identification performance by reducing the occurrence of collisions. We describe the proposed solution for the single-reader scenario and then provide the guidelines to extend the enacted Q-algorithm to multi-reader systems. In particular, we describe the reader synchronization policies and empathize how the readers’ cooperation paradigm is essential for the development of an efficient and reliable RFID multi-reader system.
In the second case, the novel CS-based solution combines UWB information to reduce the total amount of time slots spent for tag identification [10]. Indeed, CS [11, 12] has been proposed as an alternative to the state-of-the-art FSA approach, which does not need to avoid collisions. However, when considering large tag population as in common RFID applications, the main problem in CS is to reduce the ID search space. We divide all the tags in groups, which are associated to UWB group codes. The UWB module, which operates at chip level, is used to quickly estimate the number of tags with data to transmit and to rapidly recognize the group codes they belong to; the UHF module, that operates at bit level, is used to identify the tags through a CS procedure. Moreover, we model and evaluate the effect of timing synchronization error on the proposed solution. Both standard-based ISO/IEC 18000-6 and CS approaches benefit from tag population estimation to minimize the total number of time slots spent by the reader for tags’ identification.
Besides the single-reader scenario, we extend our work in the multi-reader scenario. Indeed, some applications are characterized by the deployment of large populations of tags, and single-reader systems may not be sufficient to cover the area of interest. Thus, multi-reader solutions have been proposed to overcome limitations of a typical single-reader system. We here consider and model several interference problems that are absent in the case of a single-reader scenario and investigate possible solutions to face with these issues.
The rest of the paper is structured as follows. Section 2 describes the state-of-the-art multi-reader systems, while Section 3 provides the features of the hybrid UWB/UHF architecture. The single-reader scenario is described in Section 4, where both the proposed FSA- and CS-based solutions are described, and in Section 5, the extension of the proposed algorithms to the challenging multi-reader scenario is detailed. Finally, some comments on the presented results are detailed in Section 6, and future perspectives conclude the paper in Section 7.
2 Related work
Unlike single-reader systems, where tags are the only interfering entities, in multi-reader scenarios readers and tags are both interfering and interfered entities. Thus, different kinds of collision problems arise and have to be handled to properly analyze the systems and achieve adequate performance. Different approaches have been proposed to mitigate and solve the so-called reader collision problem (i.e., a reader is the interferer and either a tag or another reader is the interfered entity). The most popular anti-collision approaches for multi-reader systems are summarized in Fig. 1.

Multi-reader anti-collision approaches
One of the first proposed protocols to contrast reader collisions is a time division multiple access (TDMA) technique known as Colorwave [13]. Colorwave is a distributed algorithm in which each reader chooses a random time slot used for query transmissions. If two readers choose the same time slot, a collision occurs. In this case, a colliding reader chooses a different time slot and forwards a message to its neighbor readers to notify such a change. The main drawback of this approach is the required time synchronization between readers.
ETSI EN 302 208 [14] standard adopts a Carrier Sense Multiple Access (CSMA)-based approach known as Listen Before Talk (LBT). Before transmitting a query, the reader senses the channel for a specified amount of time. If the channel is sensed idle, the reader begins the reading procedure; otherwise, it waits a random back-off time waiting for the channel to become idle. Note that, as in traditional carrier sense-based protocols, LBT suffers for the hidden terminal problem and thus may not be able to detect and solve collisions. Authors in [15] propose a beaconing-based technique called Pulse that does not offer for the hidden terminal process. This protocol relies on the presence of two non-interfering channels. A control channel is reserved for reader-to-reader communication, while a data channel is used for identification process. When a reader is in the reading phase, simultaneously broadcasts a beacon over the control channel to notify the ongoing communication in order to prevent neighbor readers to transmit over a busy data channel. This protocol may result in high delay when the number of readers is large.
Also frequency division multiple access (FDMA)-based approaches can be adopted to mitigate reader collision problems. Unfortunately, FDMA-based protocols are only effective in solving reader-reader protocols unless the tags have frequency selectivity, which is not the case of passive systems. The standard EPCglobal Generation2 suggests the use of FDMA for multi-reader operations but does not specify how to coordinate the network of readers. However, the ETSI regulation dictates that readers can transmit over a specific channel only for a limited amount of times; thus, reader coordination strategies should take into account this limitation imposed by the standard.
An approach based on learning theory is proposed in [16]. In particular, the authors develop an online algorithm called Hierarchical Q-Learning (HiQ) that dynamically assigns frequency channels based on readers’ access patterns observation. The algorithm attempts to find an optimum frequency assignment in order to prevent collisions to neighbor readers. The optimization problem is solved by means of a particular type of reinforcement learning called Q-learning.
Finally, great research effort has been recently devoted in finding Medium Access Control (MAC) solutions for multi-reader systems, by allowing networked readers to operate either concurrently or cooperatively with the common goal of improving systems interrogation performance and reliability. Some examples of optimal reader activation scheduling can be found in [17].
In this paper, we propose to use a hybrid UWB/UHF architecture to improve tags’ identification both in single-reader and multi-reader scenarios. We develop two solutions: the first one exploits UWB signals to enhance the standard ISO/IEC 18000-6C UHF, the second one exploits UWB to improve the CS-based solution.
3 UWB/UHF hybrid architecture features
3.1 Opportunistic UWB signal
The tag population cardinality is in general unknown. Counting the number of tags within a certain region is one of the key problems strictly related to the tag identification process. While its usefulness is evident in those applications where it is desirable to only count the number of RFID tags, estimating the tag population cardinality provides a useful support in any case. In [18], the cardinality estimation problem is analyzed in two different versions: the single-set RFID counting problem and the multiple-set RFID counting problem. The single-set problem is directly connected to single-reader systems, while the multi-set counting problem arises in multi-reader systems or in a system for which a single mobile reader probes different interrogation areas.
Different counting approaches and protocols have been proposed in the literature. In [18], the authors point up that all the proposed techniques are based on a common approach of dividing the counting process in rounds. Within rounds, the number of tags can be estimated from various statistical metrics extracted from the observed tags’ response patterns. The development of accurate and efficient counting protocols requires, in general, two estimation phases. The idea is to start with a rough estimation during the first phase and refine the result in a second phase to achieve the desired accuracy.
Very fast, reliable, and efficient tag population estimation can be achieved by employing UWB backscattering communication [19, 20]. In particular, backscattering communication uses modifications of antenna reflection properties at the tag to transmit information. In general, due to the short pulse duration (typically less than 1 ns), the bandwidth of the transmitted signal can be on the order of one or more gigahertz (GHz).
The UWB signal transmitted to a tag is modulated using an antipodal pseudorandom binary code to uniquely identify the reader (reader’s code). The UWB pilot signal is backscattered by the tag as well as by all the surrounding scatterers in the environment. In particular, at each chip time, the backscattered signal associated with the kth tag is modulated by the combination of reader’s and tag’s codes. Differently, the environmental reflected signal (i.e., clutter components, which includes the structural antenna mode) exhibits modulation only by the reader’s code. The pulse repetition period is typically chosen so that all signals backscattered by the environment are received by the reader before the transmission of the successive pulse. In indoor scenarios, a 100-ns repetition interval is usually sufficient to this purpose [21].
Consider a reader that interrogates a set of tags in its communication range by transmitting an UWB signal with a specific spreading code. For population estimation, it is reasonable to consider that tags share the same code. Considering that all tags backscatter in the same way, the estimation of the tag population is related to the analysis of the energy collected by the UWB receiver at the reader. Due to the different times of arrival (ToA) of the backscattered signals from nodes at different distances, the reader may be able to distinguish the presence of tags at different distances. The tag population estimate results in estimating the number of backscattered pulses, although the channel delay spread should be accounted for in a realistic propagation scenario. Using different codes on the tag side may improve the detection performance, while increasing complexity. The accuracy is measured in terms of maximum estimation error on the interrogation ranges, which returns an error on the number of tags actually present within a given range. In a next phase, assuming that a tag has been identified, by measuring the ToA of the backscattered signal, the reader is able to estimate the distance (ranging operation) and then provide an input to one or more algorithms for estimating the position of the tag.
The integration of classic UHF architectures and backscattering UWB communication enables the development of interesting solutions from a MAC layer perspective. Indeed, fast tag population estimation can be used as a support for the interrogation process, improving collision resolution techniques provided by the existing standard. In particular, referring to EPCglobal Generation 2 protocol, UWB technology allows to overcome drawbacks of the adaptive Q-algorithm, which provides dynamic frame length update only based on the observation of collided and idle slot patterns. On the contrary, having an available estimate of the number of tags involved in the interrogation process allows to develop more efficient frame length update algorithms for framed ALOHA-based MAC protocols.
Moreover, UWB backscattering can be successfully employed as the core technology in developing multi-reader cooperative systems. Classical MAC solutions presented in this field are based on concurrent readers’ operations. However, more efficient and robust solutions may be developed by allowing readers to cooperatively operate for targeting some common performance requirements. In this perspective, ranging and tag population estimation are required informations for designing cooperative reader networks for large-scale RFID systems characterized by real-time requirements, high identification reliability, and accurate localization.
UWB backscattering communication allows for multi-reader cooperative solutions that can effectively improve system efficiency and robustness.
3.2 System architecture
The hybrid UHF/UWB system architecture and the propagation scenario are the same considered in the framework of GRETA project [8] and are illustrated in Fig. 2.

System architecture
Hybrid UHF/UWB reader. The reader is equipped with an UHF front end for UHF domain operations. In particular, the reader relies on the UHF band for tag energization, synchronization, and inventory commands as in classic EPCglobal Generation 2-based systems. We assume that the reader has online power control and multi-frequency communication capabilities. These features are needed to mitigate interference problems in multi-reader systems as we discuss later in the paper.
In the UWB domain, the reader is equipped with a full IEEE 802.15.4a-based communication system (e.g., Decawave DW1000 [22]). As we discuss later in the paper, this communication structure is needed to exploit readers’ cooperation (i.e., data exchange between readers) and readers discovery in multi-reader scenarios.
Furthermore, the reader is equipped with a UWB backscattering communication system used for tag population estimation and ranging. Note that the UWB transceiver increases the reader complexity and the energy consumption. However, the additional energy requirements are limited to UWB backscattering communication epochs and the related consumptions are very small if compared to those of the UHF band. Moreover, the reader’s architecture constraints in terms of circuitry overhead and energy efficiency are usually much more relaxed if compared to those of the tag architecture. Consequently, we do not consider complexity limitations on the reader design and we mainly focus on keeping the tag complexity as small as possible, as required by the passive architecture paradigm. The design and a prototype implementation of an efficient backscattering receiver are under development and are major objectives of the GRETA framework.
A control logic unit is required to properly coordinate the operations in the two different domains, and again, we assume two logically separated antennas for UHF and UWB operations.
Hybrid UHF/UWB tag. In the UHF domain, a passive tag collects the power from the RF signal transmitted by the reader (i.e., tag energization). The energy-harvesting unit and the storage module (i.e., usually a small capacitor) are used to provide energy supply for tag operations. Communication in the downlink (i.e., tag-reader link) takes place in a backscattered fashion. In particular, the tag interprets the reader’s command by means of the UHF demodulator and sends data back by switching the impedance of the antenna, typically between two states, thus modulating the backscattered UHF signal. In the UWB domain, the already energized tag may transmit back information by modulating the backscattered UWB pulses, similarly to the UHF domain, by switching impedance of the relative antenna.
The tag is equipped with a hybrid UHF/UWB antenna to properly operate in the two domains. We assume that the UHF and UWB antenna components are logically decoupled but can be implemented as a single physical antenna system. Details about hybrid antenna structures and fundamentals on backscattering communication can be found in [23, 24]. Note that the additional circuits on hybrid tags consist of only the impedance switch for UWB backscattering modulation and the related control logic for orchestrated UHF/UWB operations. Thus, the overall circuitry overhead is relatively small and characterized by limited additional energy cost. A discussion on different tag implementation alternatives and the relative performance description in terms of energy consumption and circuitry complexity can be found in [9] and references therein.
Furthermore, the UWB/UHF decoupling allows to keep the tag in active state during UWB backscattering operations. Indeed, given the logical separation between the two bands, UHF energy can be exploited to continuously power the tag. On the other hand, the tag’s capacity drops only during UHF backscattering operations (i.e., responses to query commands during the identification phase). However, UHF backscattering response is a low-duty cycle process and, consequently, the coexistence of UWB and UHF bands does not consistently degrades the operational range of the tag.
Given the definition of the tag UWB module, the backscattered signal at the reader’s receiving front end, which accounts for the contributions of the tags in the covered area, can be expressed as an infinite sequence of pulses separated by T f seconds (frame time) as [4] follows:
where K is the number of tags to be identified, r k(t) is the received backscattered signal from the kth tag, n(t) is the additive white Gaussian noise (AWGN), d n is the reader’s code, and ω (c)(t) is the backscattered version of the transmitted pulse due to the clutter component, which accounts for pulse distortion, multi-path propagation, and tag’s antenna structural mode.
By assuming that all tags are synchronous (i.e., Δ k=0), the kth contribution to the received signal defined in (1) is
where N pc is the reader’s code length, N x is the number of pulses associated to half synchronization error safeguard, \({d_{m}^{k}}\) is the code of the kth tag, ω k(t) is the backscattered version of the transmitted pulse coming from the kth tag, and T c is the chip time. In general, ω k(t) accounts for pathloss, multi-path, and delay induced by propagation channel.
Note that, according to different purposes, we can assume a different set of tag codes. For example, the tags may be associated to different codes \({d_{m}^{k}}\) for identifying the tags by only using the UWB module, or they can use the same code d m for tag population through an energy estimation.
Table 1 shows a schematic overview on how the reader features are exploited by the enhanced Q-algorithm and the compressive sensing approaches for both single-reader and multi-reader systems. Observe that tags are compatible with readers operation given the considered architecture.
4 Single-reader scenario
In a single-reader scenario, the operations on the UHF domain and UWB domain can be illustrated as follows. In the UHF domain, a passive tag collects power from the RF signal transmitted by the RFID reader and sends data back by modulating the backscattered UHF signal. In the UWB domain, the already energized tag transmits back information by modulating the backscattered UWB pulses. The UHF and UWB links can operate simultaneously both on the reader’s and tag’s side. Here, the reader uses UHF for identification, while the UWB technology is adopted for tag population estimation.
An interrogation round is defined as a sequence of consecutive commands and responses that are issued by a single reader and replied back by the tags in order to transmit the tag IDs to the reader. A sequence of consecutive interrogation rounds forms an interrogation session.
4.1 Enhanced ISO/IEC 18000-6C UHF
The time evolution of the algorithm is illustrated in Figs. 3 and 4 and described in the following.
-
1.
Initially, the reader transmits a continuous wave UHF signal (CW) to power up the tags in its maximum transmission range RangeMax. The maximum transmission range is application dependent and is limited by FCC/ETSI regulations.
Fig. 3 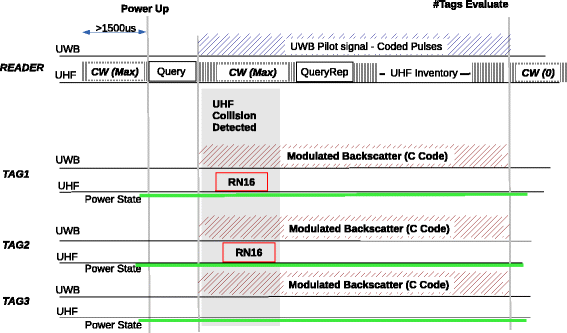
Standard UHF inventory in the first estimate of active tag number
Fig. 4 
Example of UWB and UHF signal in the adaptive Q-algorithm, highlighting the UWB link tag use, the estimated number of tags (c code) and ranging (c ∗ code)
-
2.
As soon as the nodes are powered (i.e., T pw≈1500 μs), the interrogation starts by following the standard ISO/IEC 18000-6C protocol. Together with the first Query command, the reader starts transmitting a sequence of UWB pulses and the tags respond by modulating the backscattered UWB signal using the c code.
-
3.
The reader interprets the received backscattered signal and estimates R a n g e0 and R a n g e1, namely the interrogation ranges that contain N 0 and N 0+N 1 tags, respectively.
-
4.
The reader then selects Q=[ log2N 0], where [ ·] denotes the nearest integer function, and sends the next Query command with sufficient power to interrogate tags in R a n g e0.
-
5.
Between consecutive Query commands, while interrogating tags in R a n g e0, the reader continues the UWB ranging procedure by considering R a n g e1 and R a n g e2, which includes further N 2 tags. The UHF transmission power is set to also reach tags that are interrogated in the next Query. By doing so, those tags are already powered when receiving the Query command.
-
6.
After N 1 tags have been identified, the reader increases the transmission power of the following Query command to reach tags in R a n g e1 and, similarly, after N 1+N 2 tags have been identified, the transmission power is increased to include R a n g e2. In this way, the average number of activated tags in different stages of the interrogation is kept between N 0−N i and N 0. Notice that already identified tags stop responding to query commands and refrain from backscattering modulated UWB pulses in the same interrogation session.
-
7.
The transmission range is increased every N i successful interrogations until it reaches RangeMax and the session ends when all tags have been identified.


We recall that the proposed mechanism is compliant with the ISO/IEC 18000-6C specifications for both the reader and the tag. The optimal choice of the parameters N i is not straightforward. Every time the reader includes new tags, it has to issue a Query command instead of a shorter QueryAdj command. Therefore, if N i is too small, the interrogation time and the energy consumption are negatively affected.
4.2 Enhanced compressive sensing identification protocol
A novel tag identification protocol based on compressive sensing and UWB has been presented in [10], and it is briefly summarized in the following.
We consider a hybrid UWB/UHF tag architecture, where an UWB module helps the UHF-CS procedure for tag identification by reducing the time required for tag identification and by decreasing the complexity of the UHF-CS scheme. In particular, the tags are divided in groups, and both tags and groups are associated with codes for their identification. Specifically, group codes are communicated from tags to the reader in the UWB domain, while tag codes are sent in the UHF domain.
UHF signals are used for tag identification through a CS procedure, while UWB signals are exploited for fast groups identification and tag population estimation in order to reduce the UHF-CS search space size. Moreover, tag population and the number of group are useful information to adapt to the length of the tag ID codes. In this way, the UHF-CS procedure for tag identification becomes faster and simpler.
4.2.1 UHF-CS model
We consider a large backscatter RFID network with tag population N, where only a limited amount of tags K have to be identified.
The tag identification process is performed in the UHF domain and usually utilizes temporary IDs [11, 25]. Indeed, the globally unique ID, i.e., the one printed on the tag, is often long, while the temporary ID is shorter because the uniqueness needs to be kept only for the tags that want to transmit at the same time. As an example, the EPC Gen-2 standard [25] uses 16-bit temporary IDs during the identification phase [11, 25], so that the size of the temporary ID space is equal to N max=216.
Each tag chooses a temporary ID among N. A binary vector x of size N is defined, where x j =1 if tag j is one of the K tags to be identified, and x j =0 otherwise. Therefore, ∥x∥0=K, since there are K non-zero elements in x. We want to identify the elements j for which x j =1.
After receiving a start command, i.e., a Query from the reader, each tag for which x j =1 uses its ID as a seed in its hash function [12] to generate a M×1 pseudorandom binary vector c j . c ij ∈{+1,−1} are the elements of c j , where i=1,2,…,M, and M denotes the number of bits required for successful identification of the K tags. Specifically, the tags continue by generating a random bit and transmitting it until the reader verifies that a given length M has been reached. Then, the reader triggers the tags to stop transmitting, which can be done by simply stopping its RF signal that powers on the tags.
By gathering all vectors c j in the coding matrix, C=[c 1 c 2…c N ] of size M×N, where M<N, we have that the received measurement vector y at the reader is given by
where z=H x and H is the diagonal channel matrix, whose elements H jj =h j denote the complex channel coefficients for tag j. Indeed, since each tag transmits in a narrow band channel (640 kHz), its channel can be modeled as a single tap channel [25]. However, as described in Section 4.2.2, we also analyze the case of timing synchronization errors, for which H considers the resulting inter-symbol interference (ISI).
The reader uses a CS-decoding scheme to estimate the elements of vector z. The estimation of z is formulated as an optimization problem [26]
where ∥.∥1 is the l 1 norm. To guarantee stable recovery in the presence of noise, the number of measurements M, i.e., the length of the ID code associated to a tag, must obey
where α is a constant [26]. However, this condition imposes a prohibitive large value of M and N, the whole ID search space. For this reason, it is needed to reduce the ID search space before employing CS techniques.
Even then, the 16-bit sequence of RN16 IDs are not used in CS-based protocols, since in general they will not fulfill the necessary condition (5) for successful recovery. This is the reason why M-length pseudorandom sequences are generated and transmitted in place of them.
A drawback of CS-based protocols is that such pseudorandom sequences have to be received synchronously at the reader. Anyway, the tags can be synchronized by exploiting the reader’s query that trigger the tags, but the jitter in detecting the reader’s signal can lead to initial offsets.
In the following section, Section 4.2.2, in order to evaluate the effect of such offsets on the UHF-CS procedure, we model the timing offset as an ISI at time slot level among the backscattered signals from the different tags. The ISI effects results in a non-diagonal channel matrix H (see Section 4.2.1).
Note that we analyze the synchronization issue only for UHF signals, since it is negligible for UWB signals in the way they are employed in the presented solution, as specified in Section 4.2.4.
4.2.2 Timing synchronization error model
In this section, we model the timing synchronization error in the UHF domain. The Farrow structure (see Fig. 5) of the interpolation filter consists of L+1 parallel FIR branch components with fixed coefficients having transfer functions C l (z), for l=0,1,…,L, and only one variable parameter μ. The parameter L is the degree of the polynomial while μ represents the fractional delay timing error correction. The impulse response of the interpolator in each sampling time interval \(T_{s}=\frac {T}{2}\), where T is the symbol time, is

Farrow structure for the interpolation filter
The output of the Farrow scheme is
where
and N, the Farrow branch filter length, is equal to the filter order plus 1. h(i) is the element of the vector h, and H is the convolution matrix of h, which accounts for the ISI due to timing synchronization error, and it is used in (3) when accounting for timing synchronization errors, instead of the diagonal matrix.
The basic idea of this structure is that the outputs h(i) form a polynomial approximation for the continuous time signal x(t) at time instants i T=(n+μ T s ). The obvious advantage, in terms of hardware implementation complexity, is that the filter coefficients are constant and the output time sampling is only controlled by the parameter μ [27].
The design of Farrow interpolators can be done in several ways, and traditionally, it is based on Lagrange polynomials. In this work, we consider the Farrow structure for the Lagrange interpolator polynomials, as reported in [28], which satisfies the following condition:
where
and V is the Vandermonde matrix
The solution of (9) provides a filter structure in which the fractional delay μ∈[0,1] and a constant phase delay with respect to the filter order.
A more efficient construction is suggested in [29], with a new parameter range equal to [−0.5,0.5]. This can be pursued by employing the matrix transformation T
where n, m=0, 1, ⋯, L and the new filter is obtained by replacing the solution of (9) with
4.2.3 UWB model
While we use UHF signal to identify the tags through a CS procedure, we exploit a UWB signal to reduce the complexity of such UHF-CS algorithm [10].
Without loss of generality, we organize all the N tags in N g groups with size s g according to their temporary IDs.
Considering the UWB domain, we use UWB codes to identify the groups the tags belong to. Thus, according to the model in Section 3.2, the reader receives the UWB backscattered signal r(t) expressed in (1), whose kth contribution defined in (2) is replaced with
where \({d_{m}^{g}}\) is the group’s code the kth tag belongs to, which replaces the code \({d^{k}_{m}}\) in (2).
4.2.4 UWB&UHF-CS algorithm first step: estimating the number of K tags and the groups they belong to
The time evolution of the algorithm is described in the following. Initially, the reader transmits a continuous wave UHF signal (CW) to power up the tags in its transmission range.
As soon as the nodes are powered (i.e., T pw–1500 μs), the interrogation starts. Note that different from the standard ISO/IEC 18000-6C protocol, the CS procedure does not need re-transmission when a collision occurs. In particular, together with the Query command, the reader starts transmitting a sequence of UWB pulses. The K tags to be identified, i.e., the ones in the reader’s range, respond by modulating the backscattered UWB signal using the \({d^{g}_{m}}\) codes.
The reader interprets the received backscattered signal and estimates both the tag population K and the identification of the groups they belong to according to the received UWB codes \({d^{g}_{m}}\). The reader despreads the received UWB backscattering signal r(t), with reader code d n and UWB group tag codes \({d_{m}^{g}}\) according to (1) and (14) and identifies the empty/busy groups.
Moreover, estimating the received energy for each UWB group code gives an estimate of the number of K tags to be identified, even in the presence of multi-path fading effects, since we just need a rough estimation of K itself. Such estimate is used to adapt the tag code length in the UHF-CS algorithm described in the following.
We here do not consider the synchronization issue, since synchronization at chip level for UWB group code identification is not stringent because the reader’s receiver has to compute only the correlation with known groups codes to detect the groups the tags belong to; therefore, it is not necessary to recover data where the synchronization would be problematic.
4.2.5 UWB&UHF-CS algorithm second step: reducing the scale of compressive sensing
In this section, we describe the CS procedure, which is performed in the UHF domain.
Since CS moves the computational complexity from coding to decoding, a CS benefit is that the RFID tags can be quite low cost. However, the reader must handle more computing work. The decoding complexity of CS is O(N× log(N/K)) [26], which is really high when the number N of all the RFID tags is huge. On this purpose, the reader must reduce the scale of suspected RFID tags.
UWB information is here exploited to reduce the search space size of the UHF-CS procedure. Specifically, the reader interprets the received backscattered signal and estimates the group’s UWB codes \({d^{g}_{m}}\). Only the tag IDs associated with that group codes \({d^{g}_{m}}\) will remain in the search space, the other ones will be discarded, thus reducing the number of columns of the matrix C in (3). Note that tag codes forming matrix C are communicated in the UHF domain during the CS procedure for tag identification.
Let C ′ be a reduced version of the matrix C that keeps only the columns corresponding to the remaining \(N^{*}_{g} s_{g}\) possible temporary IDs, where \(N^{*}_{g}\) is the number of the groups with tags to be identified, s g is size of the group, with \(N^{*}_{g}\leq K\). x ′ and H ′ are the similarly reduced forms of x and H expressed in (3). In this way, the reader only needs to regenerate C ′, as opposed to C.
4.2.6 UWB&UHF-CS algorithm third step: tag identification through CS decoding scheme
Now that we have reduced the scale of CS problem to recovering K temporary IDs out of only K s g possible IDs at most, and according to the notation in Section 4.2.1, the system to solve in the UHF domain becomes
To decode, the reader uses CS to estimate the elements of vector z ′. Objective
subject to
The space of the problem is now N ′ as opposed to N, with N ′<N and \(N'\leq N^{*}_{g} s_{g}\), where \(N^{*}_{g}\) is the number of groups containing the K tags to be identified, and the tag code length can be reduced to
where β is a constant [10].
5 Multi-reader scenario
Large tag deployment, mobility, and real-time requirements are some peculiar aspects for a wide set of RFID application domains. Unfortunately, readers have limited energization and interrogation range, and consequently, coverage and identification performance may not be met by a single interrogator. The use of multiple readers, networked in some way, has been proposed as a viable and effective approach to address leakages and drawbacks of single-reader systems.
However, multi-reader MAC protocol design is challenging given that different kinds of collision problems arise. Indeed, unlike the single-reader scenario, in which the tag-tag collisions can be handled by classical anti-collision schemes, in multi-readers system, interference between readers leads to different kinds of collisions known as reader collisions. In a reader collision event, interference is generated by a reader and the interfered entity can be either a reader or a tag. Thus, we can distinguish two kinds of reader collision (Fig. 6): reader-tag collision and reader-reader collision. A reader-tag collision occurs when a reader is in the interference region of another reader. For example, referring to Fig. 6 b, the signal from r1 may affect t1’s response to reader r2, thus preventing correct tag identification. This kind of collision can be avoided by planning frequency channel assignment to neighboring readers or by carefully scheduling reader activation in the time domain. Similarly, a reader-reader collision event takes place when a tag is in the overlapping interrogation region of two active readers. For example, in Fig. 6 c, queries from r1 and r2 may collide at tag t1, preventing t1 to correctly respond to any reader. Although readers are still able to read tags in their interrogation regions, the reading process may result in wrong identification of those tags within the overlapping areas.

Collisions in multi-reader RFID systems. a Tag-tag collision. b Reader-tag collision. c Reader-reader collision
Reader’s cooperation can be exploited to mitigate the described problems.
The general multi-reader scenario is depicted in Fig. 7 a, where a set of networked readers scan a certain region of interest. In this case, readers can exchange ranging and population information in order to perform efficient tag identification. For instance, readers can adjust interrogation ranges in order to mitigate interference and improve identification performance.

Readers cooperation. a General readers’ network. b Readers’ cooperation for ranging and localization
A particular case of the general scenario is depicted in Fig. 7 b, where one reader acts as an “illuminator” (i.e., provides tag energization and synchronization) and the other ones are enabled for collecting UWB tags’ responses for ranging and localization purposes.
In what follows, we refer to the general scenario and consider the conditions under which it can be reduced to the particular case of Fig. 7 b. We further provide the guidelines on how to extend the enhanced Q-algorithm to the multi-reader scenario based on the system architecture described in Section 3 and exploiting reader cooperation. Finally, we extend the CS approach described in Section 4.2 to multi-reader systems.
5.1 Enhanced Q-algorihm
We consider the readers’ network depicted in Fig. 7 that is structured as a wireless sensor network (WSN) relaying on the IEEE 802.15.4a protocol. Without loss of generality, we focus on a small portion of the network, that consists of four readers operating under the following main assumptions:
-
1.
Nomadic environment: when not operational, one or more readers could change their position in the network;
-
2.
Antenna model: each reader is equipped with a steerable antenna. We consider an ideal flat-top antenna model [30] with main lobe beam-width θ and no secondary lobes. The antenna beam-width must be large enough to cover the interrogation region of interest (e.g., θ ≥ 90° to guarantee coverage for a square interrogation region);
-
3.
The UHF coverage range r UHF is equal to the UWB coverage range r UWB (i.e., r UHF= r UWB= r). The coverage range r depends on the power emission limitation of both UHF and UWB specifications. In the UWB case, the range also depends on the processing gain of the selected codes [31].
The first assumption implies that, in general, readers in the network are not aware about the presence and the position of other readers. Consequently, we define a reader discovery phase. During this phase, neighbor readers identify themselves by exchanging information to determine their relative position in the network. At this stage, readers also exchange information for negotiating their UWB codes for backscattering communication operation that will be used to perform multiple access under code division multiple access (CDMA) technique. The information exchange during the discovery phase completely relays on UWB communication. For instance, to achieve very fast reader communication, the discovery phase can be implemented by exploiting the IEEE 802.15.4a protocol features.
Note that readers should be able to direct their antenna beams toward the desired direction in order to determine the scanning area to be covered. Techniques to achieve this feature are beyond the scope of this paper. In what follows, we assume a static scenario where the discovery phase has been successfully completed and all the readers have their antenna beams pointed toward the correct direction. To avoid the presence of uncovered interrogation areas, we further assume a square total interrogation region with maximum dimension \(d_{\max {=}}2r/\sqrt {2}\) and we suppose that the tag population is confined within this area.
Once the reader network has been established, two possible operating regimes can be distinguished, namely the tag identification regime and the tag localization regime. The particular operating regime of the multi-reader system depends on the ratio between the readers coverage radius r and the interrogation area dimension d. The two operative scenario are described in details in the following.
Tag identification regime When the distance between adjacent readers is exactly equal to d=d max, the system is unable to localize tags in the space. This is due to the fact that no point within the interrogation area can be covered by at least three readers simultaneously (Fig. 8). Thus, only ranging and identification are possible in this particular scenario.

Localization regime: limit case
The identification procedure for this case is performed by exploiting the enhanced Q-algorithm features described in Section 4.1. In particular, each reader separately runs the enhanced identification protocol scanning its own interrogation region. Observe that, to adapt the enhanced Q-algorithm to the multi-reader scenario in the spatial division multiple access (SDMA) hypothesis, readers need to cooperate in order to choose the proper power sweep step during each phase of the algorithm. In particular, each reader identifies tags within R a n g e i and simultaneously scan R a n g e i+1 for ranging estimation. If uncoordinated, this procedure may lead to undesired overlapping scanning areas. Consequently, after each algorithm iteration, readers flood the gathered information over the readers’ network, exploiting 802.15.4a underlying structure. Based on this knowledge, readers can adapt the protocol parameters when performing the next power sweep iteration trying to avoid overlapping among scanning areas.
The time required for each reader to complete the current algorithm step depends on the chosen Q, which in turn depends on the number of tags involved. Based on ranging information, readers can set their interrogation ranges such that the considered number of tags is about the same for each reader. Thus, all the readers terminate the power sweep step at the same time plus a small time offset, and it is possible to exchange information through the readers’ network without the need of additional UWB transceivers in the proposed readers’ architecture. If at least one reader terminates its algorithm iteration later with respect to the other, the described procedure may become inefficient. The delayed reader will provide acquired information later, thus the current adaptation step has to be done with missing information. A statistical analysis of the step duration, conditioned to the number of tags involved in the step, is beyond the scope of this paper.
Note that if the readers are well coordinated, the described procedure effectively mitigate the reader-reader collision problem by decoupling the scanning area explored by each reader. Indeed, if readers properly coordinate power control during the interrogation phase, the number of overlapping areas can be drastically reduced, thus cutting down the reader-to-reader interference. The problem of finding an optimal power sweep policy can be solved by exploiting readers’ cooperation. The derivation of the optimal power control policy is beyond the scope of this paper and will be presented in future analysis.
We stress the fact that, assuming that an optimal power control policy exists, the performance of the multi-reader system strictly depends on the performance of a single-reader system in terms of tag speed identification and query success rate. Indeed, if the interrogation areas decoupling is guaranteed, the multi-reader scenario can be analyzed as a superimposition of four independent single-reader systems. Furthermore, the reader-to-tag synchronization scheme proposed in [1] can be applied in the multi-reader scenario.
We remark that performance can be further improved when r≤d<d max. Indeed, in this scenario, the system is able to estimate the tags’ position within certain regions (Fig. 9). Consequently, localization information can be opportunistically used to refine the decoupling and the power sweep operations during the inventory phase.

Localization regime: general case
Finally, we observe that the reader-tag interference problem is not completely solved by the described procedure even if coordinated power sweep may mitigate it. However, if we again assume the existence of an optimal decoupling and power sweep scheme, reader-tag collisions can be easily solved by allowing readers to operate on different frequency channels.
Tag localization regime When the distance between readers is d<r, only one reader is sufficient for identification purposes. Indeed, the coverage range r is large enough to energize and interrogate the whole area of interest and relaying on only one reader referred to as “illuminator” (Fig. 10). The presence of other readers can be exploited to accurately localize the tags in the space. Readers that only give support for localization are denoted by “anchors.” In this paper, we do not explicitly consider tag localization performance. However, analysis on localization accuracy is one of the main topics of the GRETA project, and it has been shown that an error localization below 10 cm can be achieved in many practical tag dislocation scenarios [31].

Localization regime
The identification performance are the same as the enhanced Q-Algorithm described in Section 4, and the focus for this scenario moves on tag spatial distribution estimation. Herein, we consider a mono-static approach for tag localization. In particular, after the tags are energized, each reader acquires ranging information by investing tags with an UWB signal and waiting for the backscattered reply. The obtained information are exchanged through the readers’ network, so that the readers have at least three distance measurements for each tag. Consequently, tag position can be estimated by means of some localization algorithm (i.e., trilateration-based positioning algorithms [32]).
We remark that the described approach requires synchronization between readers. Different synchronization strategies are possible. In the following, some alternatives for synchronization policies are described.
Token ring: The reader network is organized in a token ring fashion, and all the readers act as illuminators in deferred time. In particular, one reader (e.g., R1) runs the enhanced Q-algorithm, thus identifying all the tags and collecting their ranging information. Once the procedure terminates, the reader transmits the gathered information (i.e., tag IDs and relative ranging information) and a token message to the next reader in the ring. The reader that receives the token illuminates the whole interrogation region, selecting the already identified tags. For each tag, the reader acquires ranging information and passes the token to the subsequent reader, also providing its ranging measurements. The procedure is repeated until the token returns to the first illuminator. At this point, each reader is provided with at least three ranging measurements for each tag, thus enabling their localization. An example of the described procedure is illustrated in Fig. 11, where only one tag is considered. In each step, the active reader i sends the ID of the identified tag ID j and its relative distance from the identified tag d ij .

Token ring synchronization policy
UHF signaling: In this case, only one reader acts as the illuminator. Again, the illuminator initiates a Q-algorithm session. The UHF signal sent by the illuminator for reader-tag synchronization has also the role of synchronization event for the network. In particular, the anchors listen to this signal and when they receive it, they simultaneously start a UWB session for gathering ranging information. Once ranging informations are available, readers flood the measurements through the network and the illuminator starts another Q-algorithm iteration. Note that, under this synchronization policy, all the readers in the network must be able to listen to the illuminator UHF command [33]. The illustration of a single Q-algorithm step operating under UHF signaling is shown in Fig. 12.

UHF/UWB signaling synchronization policy and UWB backscattering in monostatic scenario
UWB signaling: This approach is similar to the previous one. Different from the UHF signaling, synchronization is achieved by means of an UWB preamble-like signal, thus enabling a finer synchronization. The preamble violation (i.e., the end of the preamble-like signal) indicates the start of the backscattering UWB operations (Fig. 12).
Note that with either UHF or UWB signaling, readers synchronization is obtained during the system operational phase then, better performance can be obtained if compared with the token ring approach that defers reader activation over time in a TDMA fashion.
Finally, the tag localization can be also performed following a multi-static approach. Despite requiring more complex synchronization policies, it may result in energy consumption reduction, but localization accuracy may be lower than in the monostatic approach. Herein, we do not consider the multi-static case. The interested reader is referred to [31] for a discussion on passive UWB RFID systems for tag localization.
5.2 CS for multi-reader systems
As described before, the tag collision problem in single-reader scenario can be solved by using compressed sensing techniques, which tolerate collisions differently from FSA protocols. However, CS procedures shift the complexity from the protocol to the decoding scheme at the reader and, in case of reader-reader collision, the tag would not understand the colliding queries. The CS procedure cannot be applied to the tag receiver, since it is able to perform only simple tasks.
We propose to implement a synchronized protocol where all readers operate simultaneously on the same frequency channel using the same query, thus saving time and spectrum usage. The solution of using synchronized multiple readers in a large area could be equivalent to use a single reader with a larger power, but the restriction in the maximum power allowed to the readers limits their interrogation zones, requiring for multiple readers to cover the area [34].
A similar approach has been applied to FSA tag anti-collision problem in [34]. However, the issues in the proposed CS-based protocol are different from the ones in FSA approach when using synchronized multiple readers. In particular, the open issues in a CS-based solution is the choice of the length M of random tag codes used for their identification, which has to satisfy specific CS requirement as expressed in (18).
Moving into details, the protocol consists of all readers sending the same sequence of bits in the UHF domain, i.e., the same query, to the tags. Assuming coordination among the readers, the queries are sent at the same time so that they will not cause collisions at the tags. Indeed, since the queries are made up of the same bits, the interference from close readers do not produce collisions at tag receivers, and the received signal level at the tags remains high or low depending on whether the bit transmitted by the readers is a “1” or a “0.”
If a tag is in the range of multiple readers, when receiving the common query, it will send only one response with its identification code (UHF domain). Such code will be received by the readers in the overlapping regions in the same slots since the readers’ queries are synchronized in time.
As said before, the tag identification codes are characterized by the length M. We assume that all tags will have the same ID length M. In this way, by properly choosing the seed for generating the tag ID code and the same length M of the codes, there will be a unique tag ID code also for tags that are in overlapping reader regions.
where K r is the number of tags to be identified in the region of the rth reader. Each reader may have a different number of tags to be identified in its region, and K max represent the highest value. The estimation of K max, available through UWB information, will allow a common definition of the length M of tag ID codes according to (19). M corresponds to the number of measurements needed to identify the tags in all reader regions, that is, the time spent for the identification process in this scenario. Equation (19) assures to have the same performance as in the single-reader scenario.
The seed of the random function for tag ID generation is its identification number. In this way, we assure a unique value for the seed of the specific tag, independent from the corresponding index of a certain coding matrix at the reader. Indeed, a tag in overlapping reader regions will have a different index for each coding matrix of the readers, and a lookup table will be used to assure the correspondence of the seed.
6 Numerical results and discussions
6.1 Performance of the enhanced Q-algorithm
In this section, we report the simulation results of the enhanced ISO/IEC 18000-6C against the standard protocol in terms of probability of successful identification in a single query, here denoted as query success rate, and energy consumption at the end of an interrogation session. The energy consumption is calculated at the reader, by considering the transmission power levels in the different stages for UHF and UWB channels. Both the query success rate and the energy consumption depend on protocol specifications as well as the number of tags, the distance between the tag and the reader, environment, etc. In this validation, we assume static channel conditions and zero bit error rate. Moreover, the effects of antenna polarization on the communication range of the reader are not included. The tag population is in the range N=[10−90] tags, and it is uniformly deployed in a 2D area as in Fig. 13. We assume that the tag localization regime condition described in Section 5.1 is met; thus, we can evaluate the interrogation performance as in the single-reader scenario. Localization performance analysis is beyond the scope of this paper and is not reported here. The UHF air interface parameters are set to default specifications for tag modulation rate of 125 KHz.

Reference scenario considered in simulation
The evaluation is based on various levels of accuracy for the UWB ranging operation. Results are obtained by means of Monte Carlo simulations, with 10,000 interrogation sessions for each scenario. The accuracy is measured in terms of maximum estimation error on the interrogation ranges (i.e., on the number of tags actually present in each range). The range accuracy of 1 cm can be achieved with very performing UWB modules, while 30 cm can be considered a fairly conservative value.
As shown in Fig. 14, the enhanced mechanism achieves a query success rate of 0.42 with 25 % gain with respect to the standard ISO/IEC 18000-6C for the case with high range accuracy. The gain is slightly reduced (20 %) in the case of low ranging accuracy. The energy consumption (see Fig. 15) is 20 % lower when using the enhanced mechanism with respect to the standard ISO/IEC 18000-6C thanks both to the faster identification speed and to the use of lower transmission power level. As an interesting note, there is no relevant dependency of the energy consumption on the range accuracy.

Query success rate (QSR) as a function of number of tags

Energy consumption as a function of number of tags
6.2 Performance of the UWB&UHF-CS algorithm
We consider a total number of N=8000 tags and assume that they are uniformly distributed among the readers. Moreover, only K tags have to be identified among the N tags, with \(K=\cup _{r=1}^{R} K_{r}\), where K r is the number of tags to be estimated in the region of the rth reader and R is the total number of readers.
The UWB&UHF-CS algorithm requires two types of simulations, one in the UWB domain and the other are in the UHF domain.
The UWB signal received by the rth reader is used to estimate the number of K r tags with data to transmit in its region and to detect the groups they belong to. Such information is then exploited to reduce the complexity of the CS tag identification procedure in the UHF domain. The scale reduction procedure is applied for each reader, as described in Section 4.2.5.
UWB simulation results obtained in [10] reveal that, in case of multi-path fading, the error in the estimate of K r is not negligible but it does not affect the tag identification process. Indeed, a fine K r estimation is not required, since we only need a rough estimate to adapt the tag code length M in the UHF-CS tag identification procedure as expressed in (19).
In this work, we focus on the UHF-CS simulation results. Specifically, we model the UHF channel as a single tap channel [25], since each tag transmits in a narrow band channel (640 kHz). Moreover, in the simulation, we did not keep the length of the code M fixed according to (19), but we let M to vary while maintaining the same value for all the tags. This is equivalent to consider the imperfect \(\hat {K}_{r}\) estimation obtained from the UWB as part of the algorithm. Indeed, once we estimate \(\hat {K}_{r}\) through UWB signals, we calculate M according to (19), and then apply the UHF-CS procedure to identify the tags. The UHF code length M is equal to the time slots required for CS tag identification.
Figure 16 shows the probability of tag identification P d in a multi-reader scenario. By increasing the number of K tags to be identified and the percentage of the overlapping region, the performance degrades since the sparsity degree changes. Indeed, for a given value of M, that is, equal to the number of time slots required for the procedure, when increasing the overlapping region, the number of tags to be identified per reader increases, so the number of elements different from zero increases. On the contrary, if we fixed the value of M according to the reader that covers the maximum number of tags, as expressed in (19), we assure to have the same performance of the single-reader scenario at the cost of increasing the number of time slots required for tag identification.

The proposed UWB&UHF-CS in multi-reader scenario: probability of correct tag identification varying the number of K tags and the percentage of the overlapping region between readers
Moreover, in Fig. 17, we analyze the robustness of the proposed scheme to synchronization imperfections. Specifically, we consider the timing synchronization error model for UHF signals described in Section 4.2.2. As said in Section 4.2.4, the synchronization problem is negligible for UWB signals in the way they are used in the proposed algorithm.

The proposed UWB&UHF-CS in multi-reader scenario: probability of tag identification P d varying the the percentage of timing offset between the tags and the reader
Figure 17 shows the probability of tag identification P d when varying the percentage of timing offset between the tags and the reader in a multi-reader scenario. We assume that the readers are synchronized since they may use a dedicated channel for synchronization, while the tags may have an initial offset due to the jitter in detecting the reader’s signal, which is used as a trigger to synchronize the tags. In Fig. 17, the offset varies between 0 and 30 % of the bit length. The figure shows that the impact of the offset on the performance is negligible for offset values in the range 0– 20 %. Although there is a degradation when increasing the offset, the probability of detection is good at the cost of increasing the tag code length, i.e., the time required for tag identification.
7 Conclusions
In this paper, we proposed two novel algorithms that efficiently exploit the integration of UHF and UWB radio modules to improve the performance of UHF RFID identification protocols in multi-reader, multi-tag systems. We first considered an enhanced Q-algorithm for the ISO/IEC 18000-6C UHF standard that relies on UWB-aided tag inventory. In particular, UWB ranging capabilities are exploited for tuning MAC layer parameters and interrogation power in a readers’ cooperation perspective. We showed how the considered solution outperforms the classic Q-algorithm both in terms of query success rate and energy consumption, achieving a success rate gain of 25 % and a reduction of 20 % in energy expenditure. A compressive sensing-based algorithm is also developed and analyzed in terms of correct tag identification probability. Simulation showed that the CS approach results in very fast tag identification and high robustness to readers’ interference problems and time synchronization errors among tags and readers.
References
R Alesii, P Di Marco, F Santucci, P Savazzi, R Valentini, A Vizziello, in 2015 International EURASIP Workshop on RFID Technology (EURFID). Multi-reader multi-tag architecture for UWB/UHF radio frequency identification systems (IEEERosenheim, 2015), pp. 28–35.
PV Nikitin, KVS Rao, in RFID, 2008 IEEE International Conference On. Antennas and propagation in UHF RFID systems (IEEEThe Venetian, Las Vegas, Nevada, 2008), pp. 277–288.
D Dardari, R D’Errico, in IEEE Global Telecommunications Conference (GLOBECOM). Passive ultrawide bandwidth RFID (IEEENew Orleans, LO, 2008), pp. 1–6. doi:10.1109/GLOCOM.2008.ECP.757.
D Dardari, R D’Errico, C Roblin, A Sibille, MZ Win, Ultrawide bandwidth RFID: the next generation?Proc. IEEE Special Issue RFID—Unique Radio Innovation 21st Century. 98(9), 1570–1582 (2010).
Y Zhou, CL Law, YL Guan, F Chin, in IEEE International Conference on Ultra-Wideband, ICUWB. Localization of passive target based on UWB backscattering range measurement (IEEEVancouver, BC, 2009), pp. 145–149. doi:10.1109/ICUWB.2009.5288835.
D Dardari, Pseudorandom active UWB reflectors for accurate ranging. IEEE Commun. Lett.8(10), 608–610 (2004).
M Baghaei-Nejad, Z Zou, H Tenhunen, LR Zheng, in 2007 IEEE International Symposium on Circuits and Systems. A novel passive tag with asymmetric wireless link for RFID and WSN applications (IEEENew Orleans, LA, 2007), pp. 1593–1596.
GREen TAgs (GRETA) Project—deliverable D2 (report on the first year of activity) (2014). http://www.greentags.eu/. Accessed 5 Feb 2016.
N Decarli, A Guerra, F Guidi, M Chiani, D Dardari, A Costanzo, M Fantuzzi, D Masotti, S Bartoletti, JS Dehkordi, A Conti, A Romani, M Tartagni, R Alesii, P Di Marco, F Santucci, L Roselli, M Virili, P Savazzi, M Bozzi, in Proceedings of the 2015 International EURASIP Workshop on RFID Technology (EURFID). The greta architecture for energy efficient radio identification and localization (IEEERosenheim, 2015), pp. 1–8.
A Vizziello, P Savazzi, Efficient RFID tag identification exploiting hybrid UHF UWB tags and compressive sensing. IEEE Sensors J., 1–8 (2016). doi:10.1109/JSEN.2016.2551375. Accepted for publication.
J Wang, H Hassanieh, D Katabi, P Indyk, in SIGCOMM, ed. by L Eggert, J Ott, VN Padmanabhan, and G Varghese. Efficient and reliable low-power backscatter networks (ACMHelsinki, Finland, 2012), pp. 61–72.
G Lai, Y Liu, X Lin, L Zhang, in 2013 15th IEEE International Conference On Communication Technology (ICCT). Collision-based radio frequency identification using compressive sensing (IEEEGuilin, 2013), pp. 759–763. doi:10.1109/ICCT.2013.6820476.
J Waldrop, DW Engels, SE Sarma, in ICC ’03. IEEE International Conference On Communications, 2003, 2. Colorwave: an anticollision algorithm for the reader collision problem (IEEEAnchorage, Alaska, USA, 2003), pp. 1206–1210.
Final draft ETSI EN 302 208-2 V1.3.1 (2009-12), Electromagnetic compatibility and Radio spectrum Matters (ERM); Radio Frequency Identification Equipment operating in the band 865 MHz to 868 MHz with power levels up to 2 W; Part 2: Harmonized EN covering essential requirements of article 3.2 of the R&TTE Directive (2009).
SM Birari, S Iyer, in Jointly Held with the 2005 IEEE 7th Malaysia International Conference on Communication., 2005 13th IEEE International Conference On Networks, 2005, 1. Mitigating the reader collision problem in RFID networks with mobile readers (IEEEKuala Lumpur, Malaysia, 2005), p. 6.
J Ho, DW Engels, SE Sarma, in Applications and the Internet Workshops, 2006. SAINT Workshops 2006. International Symposium On. HiQ: a hierarchical Q-learning algorithm to solve the reader collision problem (IEEEPhoenix, Arizona, USA, 2006), p. 4.
S Tang, C Wang, X-Y Li, C Jiang, in Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE international. Reader activation scheduling in multi-reader RFID systems: a study of general case (IEEEAnchorage, Alaska, USA, 2011), pp. 1147–1155.
B Chen, Z Zhou, H Yu, in Proceedings of the 19th Annual International Conference on Mobile Computing & Networking. MobiCom ’13. Understanding RFID counting protocols (ACMMiami, Florida, 2013), pp. 291–302.
P Di Marco, R Alesii, F Santucci, C Fischione, in 2014 IEEE International Conference on Ultra-Wide Band (ICUWB). An UWB-enhanced identification procedure for large-scale passive RFID systems (IEEEParis, France, 2014), pp. 421–426.
R Alesii, R Congiu, F Santucci, P Di Marco, C Fischione, in 2014 6th International Symposium on Communications, Control and Signal Processing (ISCCSP). Architectures and protocols for fast identification in large-scale RFID systems (IEEEAthens, Greece, 2014), pp. 243–247.
D Dardari, F Guidi, C Roblin, A Sibille, Ultra-wide bandwidth backscatter modulation: processing schemes and performance. EURASIP J. Wireless Commun. Netw.47(1), 1–15 (2011).
Decawave dw1000. In: [Online]. Available: Http://www.decawave.com/sites/default/files/product-pdf/dw1000-product-brief.pdf. Accessed 5 Feb 2016.
M Fantuzzi, D Masotti, A Costanzo, in 2015 European Microwave Conference (EuMC). A multilayer compact-size UWB-UHF antenna system for novel RFID applications (IEEEParis, France, 2015), pp. 255–258.
F Guidi, N Decarli, D Dardari, C Roblin, A Sibille, in 2011 IEEE International Conference on Ultra-Wideband (ICUWB). Performance of UWB backscatter modulation in multi-tag RFID scenario using experimental data (IEEEBologna, Italy, 2011), pp. 484–488.
EPCglobal Inc., EPC Radio-Frequency Identify Protocols Class-1 Generation-2 UHF RFID Protocol for Communications at 860MHz–960MHz v1.1.9. Standard (2005).
DL Donoho, Compressed sensing. Inf. Theory IEEE Trans.52(4), 1289–1306 (2006). doi:10.1109/TIT.2006.871582.
P Savazzi, P Gamba, Iterative symbol timing recovery for short burst transmission schemes. Commun. IEEE Trans.56(10), 1729–1736 (2008).
CW Farrow, in Proc. IEEE International Symposium on Circuits and Systems (ISCAS ’88. A continuously variable digital delay element (IEEE, 1988), pp. 2641–2645.
V Välimäki, in Proc. IEEE International Symposium on Circuits and Systems (ISCAS ’95. A new filter implementation strategy for lagrange interpolation (IEEESeattle, WA, 1995), pp. 484–488.
R Ramanathan, in Proceedings of the 2Nd ACM International Symposium on Mobile Ad Hoc Networking &Amp; Computing. On the performance of ad hoc networks with beamforming antennas (ACMLong Beach, California, USA, 2001), pp. 95–105.
N Decarli, F Guidi, D Dardari, Passive uwb rfid for tag localization: Architectures and design. Sensors J. IEEE. 16(5), 1–1 (2016).
S Tennina, M Di, F Graziosi, F Santucci, in Wireless Sensor Networks. Distributed localization algorithms for wireless sensor networks: From design methodology to experimental validation (InTech, 2011). doi:10.5772/38731
PV Nikitin, KVS Rao, in IEEE Antennas and Propagation Society International Symposium 2006. Performance limitations of passive uhf rfid systems (IEEEAlbuquerque, NM, 2006), pp. 1011–1014.
V Namboodiri, R Pendse, Bit level synchronized mac protocol for multireader rfid networks. EURASIP J. Wireless Commun. Netw.2010(1), 956578 (2010).
Acknowledgements
This research was supported by MiUR of Italy in the framework of the PRIN project GRETA (Grant 2010WHY5PR).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
This paper has been presented in part in the EURASIP RFID Workshop, Rosenheim, 22--23 October 2015 [1]
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Alesii, R., Marco, P.D., Santucci, F. et al. Backscattering UWB/UHF hybrid solutions for multi-reader multi-tag passive RFID systems. J Embedded Systems 2016, 10 (2016). https://doi.org/10.1186/s13639-016-0031-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13639-016-0031-0